Cluster Maintenance
Summary
Os Upgrades
Attribut to know : kube-controller-manager --pod -eviction-timeout=5m0s : when a node is timeouted and returned, all pods are destroyed and the node is clean. You can also lower the tiemout value for drai a node
kubectl cordon node-1
Kubernetes cordon is an operation that marks or taints a node in your existing node pool as unschedulable. By using it on a node, you can be sure that no new pods will be scheduled for this node. The command prevents the Kubernetes scheduler from placing new pods onto that node, but it doesn’t affect existing pods on that node
To empty the node from the remaining pods, or with other words migrate pods from a node to others for maintenance, you can use the drain command. the node will be unschedulable until you remove the restriction (drain)
'kubectl drain node-1' or 'kubectl drain node-12 --grace-period 0' to drain quickly waiting or 'kubectl deain node-12 --force' with forcing
if you want to reschedule a node, use the command uncordon
kubectl uncordon node-1
You should to know that drain contain cordon command by default, and if you want to reschedule the node just uncordon command wil be needed
if the node contain a signle pod without replicaset or daemontset... cannot be drained, but you can force the drain with --force attribut but you wil lost it
Kub Versions and Working with ETCDCTL
for maintenance versions are very important, you can see links bellow to have more informations :
https://kubernetes.io/docs/concepts/overview/kubernetes-api/ Here is a link to kubernetes documentation if you want to learn more about this topic (You don't need it for the exam though): https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api_changes.md
No component must have a superiro version than Kube API server, because component into control plane don't communicate each other but they delgate calls to api server.
more than two minor version not accepted, you should upgrade Kub component. The method recomanded is to upgrade minor version one after one, for example if you have v1.10 and you want upgrade system to 1.13, you should upgrade to 1.11 then 1.12 and eventually 1.13
If you use kubeadm, you can apply commands :
kubeadm upgrade plan (to get informations) kubeadm upgrade apply
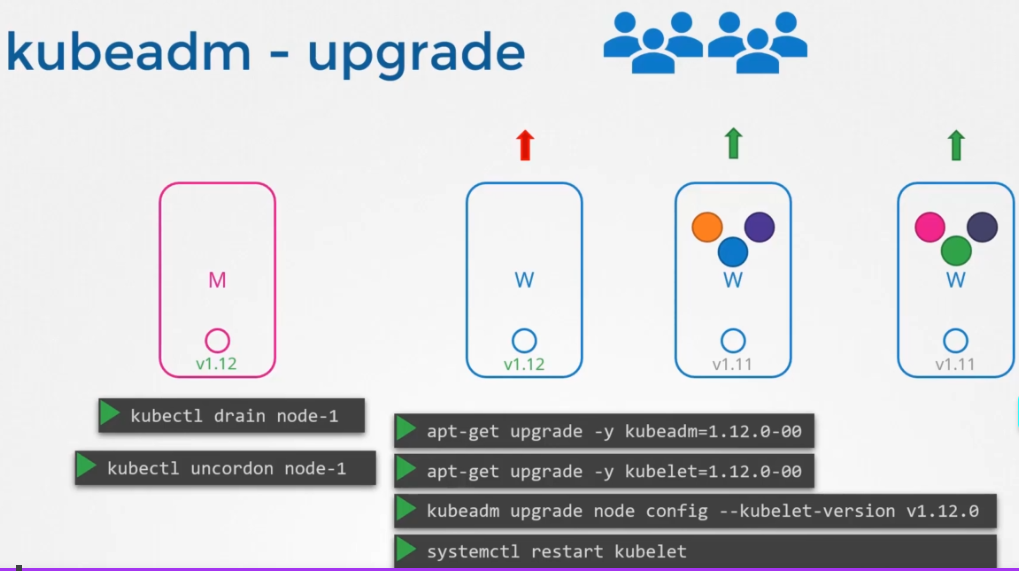
Upgrades, need to be begin by master(controlplane), the applications will not be impacted because are into workers, Then you can upgrade workers : there are 3 strategies :
- evicte all workers and upgrad them, unavailibilty time application must be accepted
- upgrade one by one avaibility is garantee
- add new nodes upgraded and migrate pods from the old one to the newone. this strategy is used in cloud (need more VMs but secure and garantee avaibility application)
Upgrade steps :
Upgrade masters first. Sometimes kubadm upgrade plan can give you command to upgrade directly to 1.13 if kube version is 1.11 for example, but you should upgrade minor version in order and not directly to 1.13, so you must upgrade to 1.12 before.
Important the kubadm upgrade command don't upgrade kubeadm itself and kublet so you should upgrade them before :
apt-get upgrade -y kubeadm=1.12.0-00 kubeadm upgrade apply v1.12.0 apt-get upgrade -y kubelet=1.12.0-00 systemctrl restart kubelet
do the samething to worker, the last command is kubectl uncordon node-1
use command to watch the status and evolution of installation of nodes
watch kubectl get nodes
Backup and Restore
- Create a backup for all ressources with command :
kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml
then there is utils to restore them like VELERO (ARK by HeptIO)
- Backup ETCD : with etcdctl snapshot save command. You will have to make use of additional flags to connect to the ETCD server. values of options can be retreaved from describe pod of etcd
ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --cert=/etc/kubernetes/pki/etcd/server.crt \ --key=/etc/kubernetes/pki/etcd/server.key \ snapshot save /opt/snapshot-pre-boot.db
--endpoints: Optional Flag, points to the address where ETCD is running (127.0.0.1:2379)
--cacert: Mandatory Flag (Absolute Path to the CA certificate file)
--cert: Mandatory Flag (Absolute Path to the Server certificate file)
--key: Mandatory Flag (Absolute Path to the Key file)
- Check status of the backup
ETCDCTRL_API=3 etcdctrl snapshot status snapshot.db
- Restore ETCD :
Stop apiserver to stop request if installation is with services : service kube-apiserver stop Restore ETCD Snapshot to a new folder ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --name=master \ --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key \ --data-dir /var/lib/etcd-from-backup \ --initial-cluster=master=https://127.0.0.1:2380 \ --initial-cluster-token etcd-cluster-1 \ --initial-advertise-peer-urls=https://127.0.0.1:2380 \ snapshot restore /opt/snapshot-pre-boot.db Modify /etc/kubernetes/manifests/etcd.yaml Update --data-dir to use new target location --data-dir=/var/lib/etcd-from-backup Update new initial-cluster-token to specify new cluster --initial-cluster-token=etcd-cluster-1 Update volumes and volume mounts to point to new path volumeMounts: - mountPath: /var/lib/etcd-from-backup name: etcd-data - mountPath: /etc/kubernetes/pki/etcd name: etcd-certs hostNetwork: true priorityClassName: system-cluster-critical volumes: - hostPath: path: /var/lib/etcd-from-backup type: DirectoryOrCreate name: etcd-data - hostPath: path: /etc/kubernetes/pki/etcd type: DirectoryOrCreate name: etcd-certs IMPORTANT :
Note 1: As the ETCD pod has changed it will automatically restart, and also kube-controller-manager and kube-scheduler. Wait 1-2 to mins for this pods to restart. You can run the command: watch "crictl ps | grep etcd" to see when the ETCD pod is restarted.
Note 2: If the etcd pod is not getting Ready 1/1, then restart it by kubectl delete pod -n kube-system etcd-controlplane and wait 1 minute.
Note 3: This is the simplest way to make sure that ETCD uses the restored data after the ETCD pod is recreated. You don't have to change anything else
if installation is a service, then :
systemctrl daemon-reload service etcd-restart service kube-apiserver start
to know wich version of etcd is installed, check the image of the pod

Ref:
https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster
https://github.com/etcd-io/website/blob/main/content/en/docs/v3.5/op-guide/recovery.md