Scheduling
Summary
- Labels and selectors
- Resource limits
- Manual Scheduling
- Taints and toleration
- Node Affinity and selectors
- DaemonSets
- Static Pods
- Multiple Schedulers
- Scheduler Events
- Confuguration of Kubernetes scheduler
Labels and selectors
Labels and selectors help us to tag and select a group of objects. For example we can add a label to pod like class=app and a service can attach to this pod by selector.
you can get objects of kubernetes by type (pod, service...) or by app like app1, 2 or by their fonctionality (frontend, db...)
Resource limits
to have a default ressources, you should create a LimitRange object :
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi (or cpu)
defaultRequest:
memory: 256Mi (or cpu)
type: Container
you can specific ressources onto the pod :
apiVersion: v1 kind: Pod metadata: name: cpu-demo namespace: cpu-example spec: containers: - name: cpu-demo-ctr image: vish/stress resources: limits: cpu: "1" requests: cpu: "0.5" args: - -cpus - "2"args section means that the containers will run in the beginin with 2 cpu
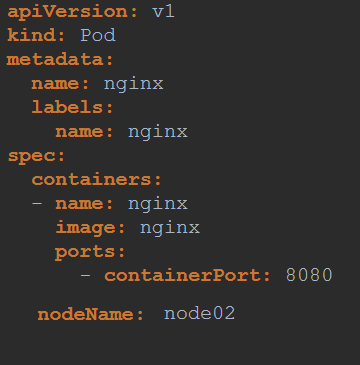
Manual Scheduling
You can schedule a pod mannualy by adding nodeName into the pod yaml desc
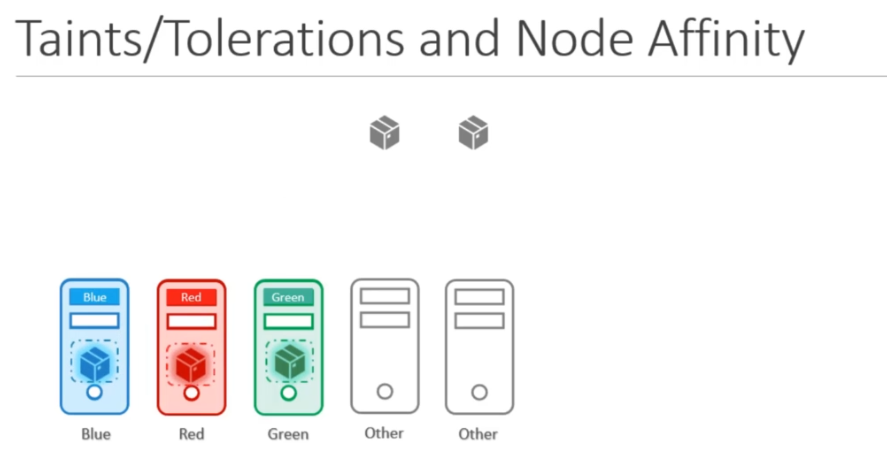
Taints and toleration
Tolerants are in pods and taints into nodes. thoses concept are used when you want a node to accepet some tolerences, but if you want a pod to accept certains nodes then we will talking about another concept called infinity or nodeSelectors.
as we can see bellow, red pod can be affected

Toleration and taints don't garantee that pods scheduled only onto those nodes. although apply tolerant a pod can scheduled onto another node.
for more details : places a taint on node node1. The taint has key key1, value value1, and taint effect NoSchedule. This means that no pod will be able to schedule onto node1 unless it has a matching toleration.
there is tree efects of taints : NoSchedule, PreferNoSchedule and Noexecute
Taint tell only to node to accept certain tolerations. You can use command bellow to taint a node
kubectl taint nodes node1 app=nginx:NoScheduleTo remove the taint added by the command above, you can run:
kubectl taint nodes node1 app=nginx:NoSchedule-- NoSchedule: if this taint is applied to a node that contains already some pod that doesn’t tolerate this taint, they are not excluded from this node. But no more pods are scheduled on this node if it doesn’t match all the taints of this node. This is a strong constraint.
- PreferNoSchedule: Like the previous one, this taint may not allow pods to be scheduled on the node. But this time, if the pod tolerates one taint, it can be scheduled. This is a soft constraint.
- NoExecute: This taint applies to a node excluding all actual running pods on it and doesn’t allow scheduling if new pods don’t tolerate all taint. This is a strong constraint.
To let the pod tolerate a node, here is the yaml file. The command kube control is to indicate key word to use into your yaml file:

Node Affinity and selectors
A node can accept some type of pods with slectors, but if you want to add other constraints, you should apply another pattern because slectors have some limits. so affinity and nodeAffinity can give us more flexibility. Affinity concept don't garantee that a node can accept only a type of pods as we can see bellow:

Example of node selectors :
to label a node and then use selctors tools, here is the example bellow :
kubectl label nodes <node-name> <label-key>=<label-value>
kubectl label nodes node-1 size=Large
the selectors are in the pod :
apiVersion: kind : Pod metadata: name: myapp-pod spec: containers: - name: data-processor image: data-processor nodeSelector size: Large
selectors vs affinity :

There is two type node affinity availabe :
requiredDuringSchedulingIgnoredDuringExecution: The scheduler can't schedule the Pod unless the rule is met. This functions likenodeSelector, but with a more expressive syntax.preferredDuringSchedulingIgnoredDuringExecution: The scheduler tries to find a node that meets the rule. If a matching node is not available, the scheduler still schedules the Pod in any node
IgnoredDuringExecution means when changing labels in nodes, we continue to execute pods
One type node affinity planned :
requiredDuringSchedulingRequiredDuringExecution : The scheduler can't schedule the Pod unless the rule is met and can't execute the pod unless rule is met.
Example of affinity in a pod bellow with rules applied.
The node must have a label with the key topology.kubernetes.io/zone and the value of that label must be either antarctica-east1 or antarctica-west1.
The node preferably has a label with the key another-node-label-key and the value another-node-label-value.
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
finnaly we can combine affinity and toleration concepts to affect specifics pods to specifics nodes
DaemonSets
DaemonSet concept means that the copy of pody is alwayse present in evry node.
uses case 1: monitoring, log viewer..
usecase 2: kube-proxy is a case of daemonset
usecase 3: networking and deployment of agents
Yaml file
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
Static Pods
We can create only pods and not other objects (services, daemonset...) into the node independantly to the controlplane or master. Only kublet and CRE(docker) can do it with a manifest in /etc/kubernetetes/manifests path.
This path we can find it in kubelet.service, attribut --pod-manifest-path or --config=kubconfig.yaml
in kubconfig.yaml, the attribut is staticPodPath: /etc.....
if we want to check the creation of pod we should use 'docker ps' command
use case : create apiserver.yaml, etcd.yaml ... so you can put files directrly into the path etc/kuberenetes/manifests
or you can use this command :
kubectl run --restart=Never --image=busybox static-busybox
--dry-run=client -o yaml --command -- sleep 1000 >
/etc/kubernetes/manifests/static-busybox.yaml
to fin path in wich pod is stored :
kubectl get pods --all-namespaces -o wide ssh nodename or ssh xxxx.xxxx.xxxx.xxxx
ps -ef | grep /usr/bin/kubelet (very important command to find the path)grep -i staticpod /var/lib/kubelet/config.yaml
then delete yaml file into the result of pathMultiple Schedulers
K8S is a flexible system, you can create other scheduler and run them in the same time. We use custom scheduler when we have some use case very complex or default conf not enouph.
Deploy addtional scheduler as a service :
wget https://storage.googleapis.com/kubernetes-release/release/v1.12.0/bin/linux/amd64/kube-scheduler
in my-custom-scheduler.service:
ExecStart=/usr/local/bin/kube-scheduler \\ --config=/etc/kubernetes/config/kube-scheduler.yaml \\ kube-scheduler.service --scheduler-name= my-scheduler-config.yamlinto my-scheduler-config.yaml
apiVersion: kubescheduler.config.k8s.io/v1kind: KubeSchedulerConfigurationprofiles:- schedulerName: my-scheduler
Deploy addtional scheduler as a pod with kubeadm:
my-custom-scheduler.yaml apiVersion: v1 kind: Pod metadata: name: my-custom-scheduler namespace: kube-system spec: containers: - command: - kube-scheduler - --address=127.0.0.1 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true image: k8s.gcr.io/kube-scheduler-amd64:v1.1the default pod is
etc/kubernetes/manifests/kube-scheduler.yaml apiVersion: v1 kind: Pod metadata: name: kube-scheduler namespace: kube-system spec: containers: - command: - kube-scheduler - --address=127.0.0.1 - --kubeconfig=/etc/kubernetes/scheduler.conf - --leader-elect=true image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3 name: kube-scheduler
check custom scheduler :
kubectl get pods --namespace=kube-system NAME READY STATUS RESTARTS AGE kube-scheduler-master 1/1 Running 0 1h my-custom-scheduler 1/1 Running 0 9s weave-net-4tfpt 2/2 Running 1 1h
the definition of pod using costum scheduler is :
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - image: nginx name: nginx schedulerName : my-custom-scheduler
Scheduler Events
Check events of scheduling objects: Use the command bellow :
kubectl get events - o wide
Also to check logs :
kubectl logs my-custom-scheduler --name-space=kube-system
Confuguration of Kubernetes scheduler
https://kubernetes.io/blog/2017/03/advanced-scheduling-in-kubernetes/
https://jvns.ca/blog/2017/07/27/how-does-the-kubernetes-scheduler-work/
https://stackoverflow.com/questions/28857993/how-does-kubernetes-scheduler-work